调度器概述
k8s scheduler 是一个控制面进程,它分配 Pod 到 Nodes。根据限制和可用资源,scheduler 确定哪些节点符合调度队列里的 Pod。然后对这些符合的节点进行打分,然后把Pod绑定到合适的节点上。一个集群内可以存在多个 scheduler,而 kube-scheduler 是一个参考实现。
所以 scheduler 主要要做的事就是根据 Nodes 当前状态和Pod对资源的需求,按照顺序运行一系列指定的算法来挑选出一个 Node。
我们可以通过下图,对上述说的列算法有一个初步的认识。
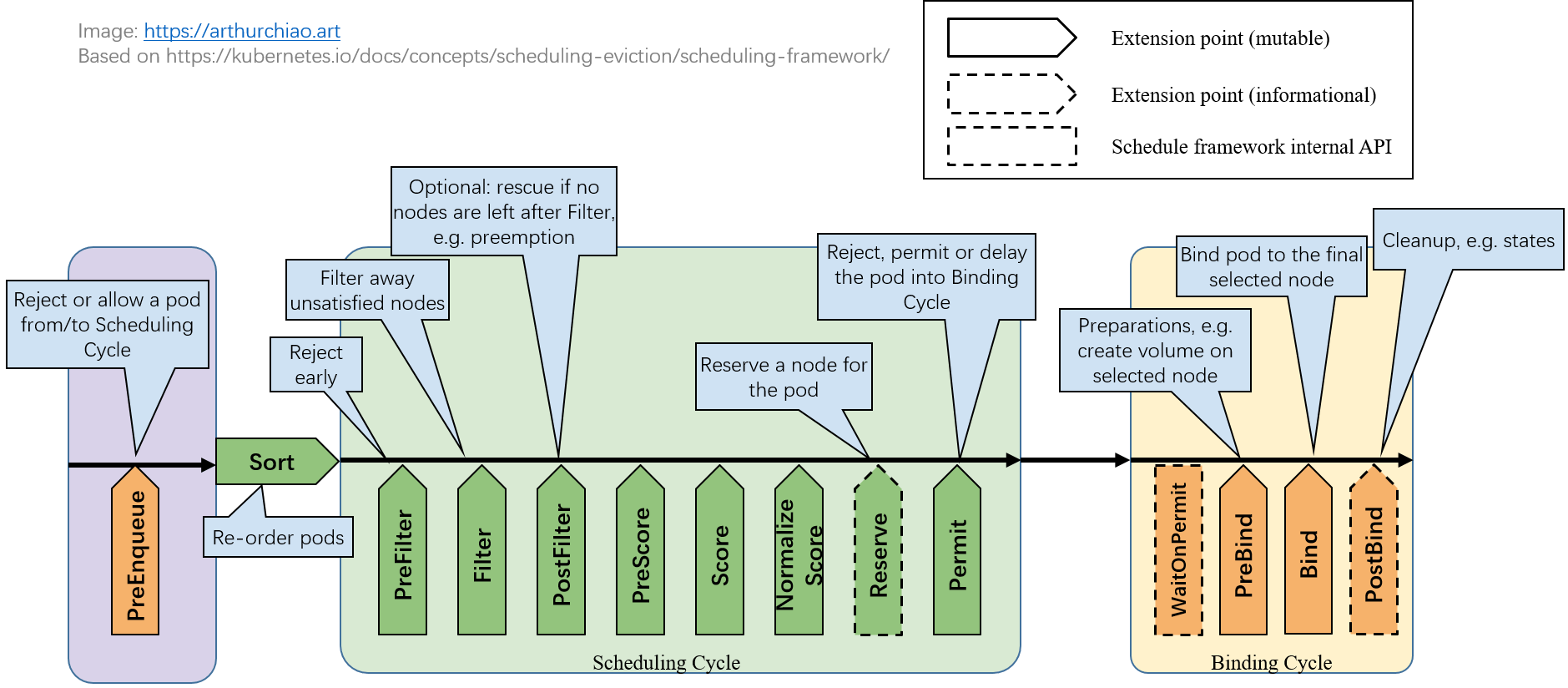
图中每一个绿色箭头在 k8s 中叫扩展点(extension point),从图中可以看到一共有 10 个扩展点。
用户可以编写自己的调度插件(scheduler plugins)注册到这些扩展点来实现想要的调度逻辑。 每个扩展点上一般会有多个 plugins,按注册顺序依次执行。
扩展点根据是否影响调度决策,可以分为两类。
-
影响调度决策的扩展点
大部分扩展点是影响调度决策的,在插件函数的返回值中包括一个成功/失败字段,决定了是允许还是拒绝这个 pod 进入下一处理阶段,任何一个扩展点失败了,这个 pod 的调度就失败了。 -
不影响调度决策的扩展点(informational)
少数几个扩展点是 informational 的,这些函数没有返回值,因此不能影响调度决策,在这里面可以修改 pod/node 等信息,或者执行清理操作。
扩展点分类说明
插件分类说明
根据插件是否维护在 k8s 代码仓库本身,分为两类。
in-tree plugins
维护在 k8s 代码目录 pkg/scheduler/framework/plugins 中, 跟内置调度器一起编译。里面有十几个调度插件,大部分都是常用和在用的。
$ ll pkg/scheduler/framework/plugins
defaultbinder/
defaultpreemption/
dynamicresources/
feature/
imagelocality/
interpodaffinity/
names/
nodeaffinity/
nodename/
nodeports/
noderesources/
nodeunschedulable/
nodevolumelimits/
podtopologyspread/
queuesort/
schedulinggates/
selectorspread/
tainttoleration/
volumebinding/
volumerestrictions/
volumezone/in-tree 方式每次要添加新插件,或者修改原有插件,都需要修改 kube-scheduler 代码然后编译和 重新部署 kube-scheduler,比较重量级。
out-of-tree plugins
out-of-tree plugins 由用户自己编写和维护,独立部署, 不需要对 k8s 做任何代码或配置改动。
本质上 out-of-tree plugins 也是跟 kube-scheduler 代码一起编译的,不过 kube-scheduler 相关代码已经抽出来作为一个独立项目:
github.com/kubernetes-sigs/scheduler-plugins
用户只需要引用这个包,编写自己的调度器插件,然后以普通 pod 方式部署就行(其他部署方式也行,比如 binary 方式部署)。 编译之后是个包含默认调度器和所有 out-of-tree 插件的总调度器程序,有内置调度器的功能,也包括了 out-of-tree 调度器的功能。用法有两种:
- 跟现有调度器并行部署,只管理特定的某些 pods
- 取代现有调度器,因为它功能也是全的。
上面我们主要从扩展点和插件方面说明了scheduler的架构。下面我们从源码架构说说scheduler是怎么工作。
下图是 kube-scheduler 代码的主要框架:
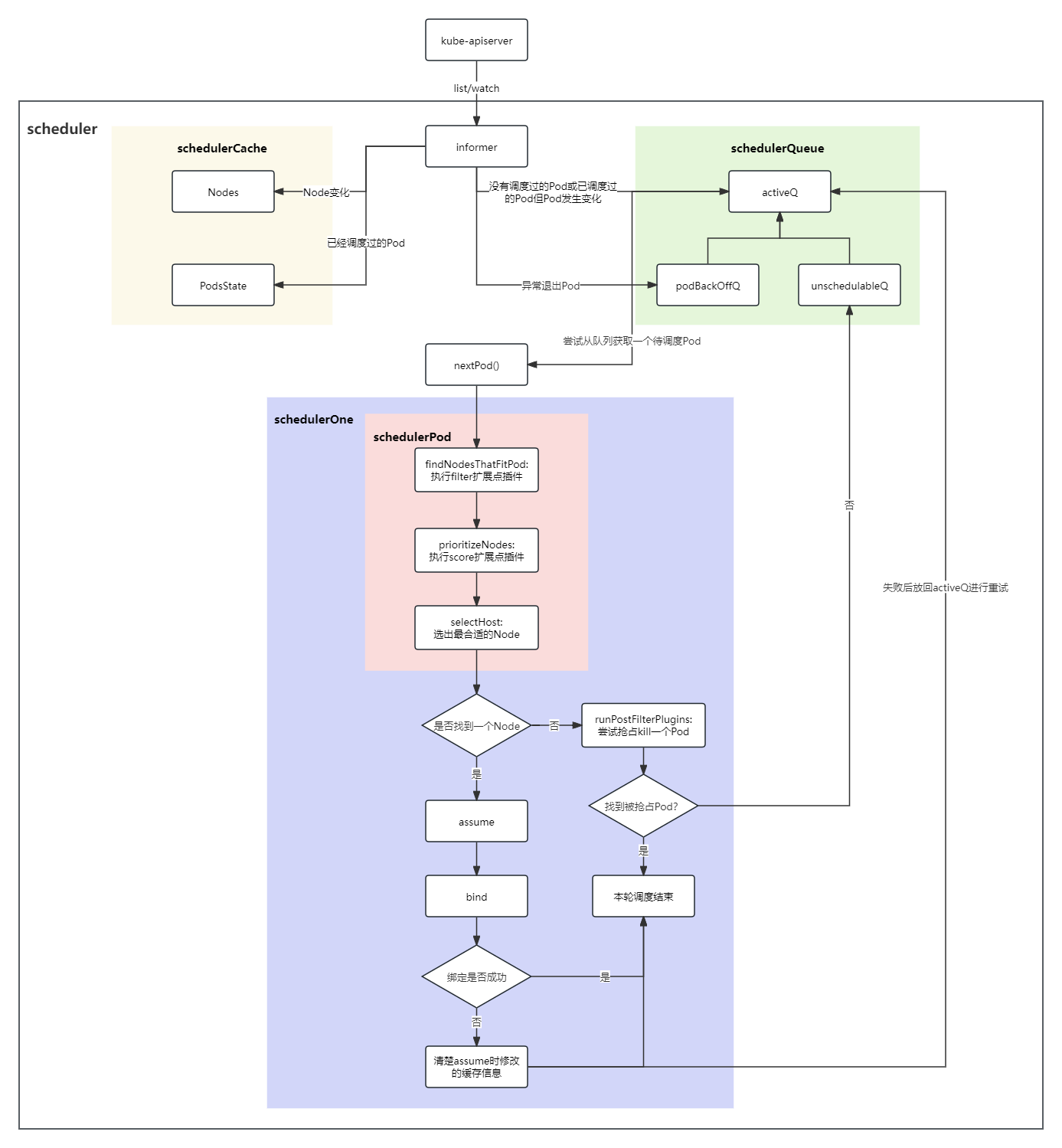
我们来看看,当一个新 Pod创建出来后,这个流程是怎么走的:
- informer 监听到了有新建Pod,根据Pod的优先级把Pod加入到activeQ中适当位置(即执行sort插件);
- scheduler 从activeQ队头取一个Pod(如果队列没有Pod可取,则会一直阻塞;此时假设就是上述说的新建的Pod),开始调度;
- 执行filter类型扩展点(包括preFilter,filter,postFilter)插件,选出所有符合Pod的Node,如果无法找到符合的Node, 则把Pod加入unscheduleableQ中,此次调度结束;
- 执行score扩展点插件,找出最符合Pod的那个Node;
- assume Pod。这一步就是乐观假设Pod已经调度成功,更新缓存中Node和PodStats信息,到了这里scheduling cycle就已经结束了,然后会开启新的一轮调度。至于真正的绑定,则会新起一个协程。
- 执行reserve插件;
- 启动协程绑定Pod到Node上。实际上就是修改Pod.spec.nodeName: 选定的node名字,然后调用kube-apiserver接口写入etcd。如果绑定失败了,那么移除缓存中此前加入的信息,然后把Pod放入activeQ中,后续重新调度。
- 执行postBinding,该步没有实现的插件没所以没有做任何事。
主要扩展点源码解析
调度阶段
Prefilter
pod 预处理和检查,不符合预期就提前结束调度。
// https://github.com/kubernetes/kubernetes/blob/v1.28.4/pkg/scheduler/framework/interface.go#L349-L367
// PreFilterPlugin is an interface that must be implemented by "PreFilter" plugins.
// These plugins are called at the beginning of the scheduling cycle.
type PreFilterPlugin interface {
// PreFilter is called at the beginning of the scheduling cycle. All PreFilter
// plugins must return success or the pod will be rejected. PreFilter could optionally
// return a PreFilterResult to influence which nodes to evaluate downstream. This is useful
// for cases where it is possible to determine the subset of nodes to process in O(1) time.
// When it returns Skip status, returned PreFilterResult and other fields in status are just ignored,
// and coupled Filter plugin/PreFilterExtensions() will be skipped in this scheduling cycle.
PreFilter(ctx , state *CycleState, p *v1.Pod) (*PreFilterResult, *Status)
// PreFilterExtensions returns a PreFilterExtensions interface if the plugin implements one,
// or nil if it does not. A Pre-filter plugin can provide extensions to incrementally
// modify its pre-processed info. The framework guarantees that the extensions
// AddPod/RemovePod will only be called after PreFilter, possibly on a cloned
// CycleState, and may call those functions more than once before calling
// Filter again on a specific node.
PreFilterExtensions() PreFilterExtensions
}- 输入
- p *v1.Pod 是待调度的 pod;
- 第二个参数 state 可用于保存一些状态信息,然后在后面的扩展点(例如 Filter() 阶段)拿出来用;
- 输出
- 只要有任何一个 plugin 返回失败,这个 pod 的调度就失败了;
- 换句话说,所有已经注册的 PreFilter plugins 都成功之后,pod 才会进入到下一个环节。
Filter
排除所有不符合要求的 node。
这里的插件可以过滤掉那些不满足要求的 node(equivalent of Predicates in a scheduling Policy)
- 针对每个 node,调度器会按配置顺序依次执行 filter plugins;
- 任何一个插件 返回失败,这个 node 就被排除了;
// https://github.com/kubernetes/kubernetes/blob/v1.28.4/pkg/scheduler/framework/interface.go#L349C1-L367C2
// FilterPlugin is an interface for Filter plugins. These plugins are called at the
// filter extension point for filtering out hosts that cannot run a pod.
// This concept used to be called 'predicate' in the original scheduler.
// These plugins should return "Success", "Unschedulable" or "Error" in Status.code.
// However, the scheduler accepts other valid codes as well.
// Anything other than "Success" will lead to exclusion of the given host from running the pod.
type FilterPlugin interface {
Plugin
// Filter is called by the scheduling framework.
// All FilterPlugins should return "Success" to declare that
// the given node fits the pod. If Filter doesn't return "Success",
// it will return "Unschedulable", "UnschedulableAndUnresolvable" or "Error".
// For the node being evaluated, Filter plugins should look at the passed
// nodeInfo reference for this particular node's information (e.g., pods
// considered to be running on the node) instead of looking it up in the
// NodeInfoSnapshot because we don't guarantee that they will be the same.
// For example, during preemption, we may pass a copy of the original
// nodeInfo object that has some pods removed from it to evaluate the
// possibility of preempting them to schedule the target pod.
Filter(ctx , state *CycleState, pod *v1.Pod, nodeInfo *NodeInfo) *Status
}- 输入
- nodeInfo 是当前给定的 node 的信息,Filter() 程序判断这个 node 是否符合要求;
- 输出
- 放行或拒绝。
对于给定 node,如果所有 Filter plugins 都返回成功,这个 node 才算通过筛选, 成为备选 node 之一。
PostFilter
Filter 之后没有 node 剩下,补救阶段。
如果 Filter 阶段之后,所有 nodes 都被筛掉了,一个都没剩,才会执行这个阶段;否则不会执行这个阶段的 plugins。
// https://github.com/kubernetes/kubernetes/blob/v1.28.4/pkg/scheduler/framework/interface.go#L392C1-L407C2
// PostFilterPlugin is an interface for "PostFilter" plugins. These plugins are called after a pod cannot be scheduled.
type PostFilterPlugin interface {
// A PostFilter plugin should return one of the following statuses:
// - Unschedulable: the plugin gets executed successfully but the pod cannot be made schedulable.
// - Success: the plugin gets executed successfully and the pod can be made schedulable.
// - Error: the plugin aborts due to some internal error.
//
// Informational plugins should be configured ahead of other ones, and always return Unschedulable status.
// Optionally, a non-nil PostFilterResult may be returned along with a Success status. For example,
// a preemption plugin may choose to return nominatedNodeName, so that framework can reuse that to update the
// preemptor pod's .spec.status.nominatedNodeName field.
PostFilter(ctx , state *CycleState, pod *v1.Pod, filteredNodeStatusMap NodeToStatusMap) (*PostFilterResult, *Status)
}按 plugin 顺序依次执行,任何一个插件将 node 标记为 Schedulable 就算成功,不再执行剩下的 PostFilter plugins。
典型例子:preemptiontoleration, Filter() 之后已经没有可用 node 了,在这个阶段就挑一个 pod/node,抢占它的资源。
PreScore
PreScore/Score/NormalizeScore 都是给 node 打分的,以最终选出一个最合适的 node,这里就不展开了。
Score
针对每个 node 依次调用 scoring plugin,得到一个分数。
NormalizeScore
给每个 node 打的分 最终必须转换为一个 [0-100] 的范围,在这一步完成该操作。
Reserve
Informational,维护 plugin 状态信息
// https://github.com/kubernetes/kubernetes/blob/v1.28.4/pkg/scheduler/framework/interface.go#L444C1-L462C2
// ReservePlugin is an interface for plugins with Reserve and Unreserve
// methods. These are meant to update the state of the plugin. This concept
// used to be called 'assume' in the original scheduler. These plugins should
// return only Success or Error in Status.code. However, the scheduler accepts
// other valid codes as well. Anything other than Success will lead to
// rejection of the pod.
type ReservePlugin interface {
// Reserve is called by the scheduling framework when the scheduler cache is
// updated. If this method returns a failed Status, the scheduler will call
// the Unreserve method for all enabled ReservePlugins.
Reserve(ctx , state *CycleState, p *v1.Pod, nodeName string) *Status
// Unreserve is called by the scheduling framework when a reserved pod was
// rejected, an error occurred during reservation of subsequent plugins, or
// in a later phase. The Unreserve method implementation must be idempotent
// and may be called by the scheduler even if the corresponding Reserve
// method for the same plugin was not called.
Unreserve(ctx , state *CycleState, p *v1.Pod, nodeName string)
}这里有两个方法,都是 informational,也就是不影响调度决策; 维护了 runtime state (aka “stateful plugins”) 的插件,可以通过这两个方法 接收 scheduler 传来的信息:
- Reserve
用来避免 scheduler 等待 bind 操作结束期间,因 race condition 导致的错误。 只有当所有 Reserve plugins 都成功后,才会进入下一阶段,否则 scheduling cycle 就中止了。 - Unreserve
调度失败,这个阶段回滚时执行。Unreserve() 必须幂等,且不能 fail。
Permit
允许/拒绝/等待 进入 binding cycle。
这是 scheduling cycle 的最后一个扩展点了,可以阻止或延迟将一个 pod binding 到 candidate node。
// PermitPlugin is an interface that must be implemented by "Permit" plugins.
// These plugins are called before a pod is bound to a node.
type PermitPlugin interface {
// Permit is called before binding a pod (and before prebind plugins). Permit
// plugins are used to prevent or delay the binding of a Pod. A permit plugin
// must return success or wait with timeout duration, or the pod will be rejected.
// The pod will also be rejected if the wait timeout or the pod is rejected while
// waiting. Note that if the plugin returns "wait", the framework will wait only
// after running the remaining plugins given that no other plugin rejects the pod.
Permit(ctx , state *CycleState, p *v1.Pod, nodeName string) (*Status, time.Duration)
}三种结果:
- approve:所有 Permit plugins 都 appove 之后,这个 pod 就进入下面的 binding 阶段;
- deny:任何一个 Permit plugin deny 之后,就无法进入 binding 阶段。这会触发 Reserve plugins 的 Unreserve() 方法;
- wait (with a timeout):如果有 Permit plugin 返回 “wait”,这个 pod 就会进入一个 internal “waiting” Pods list;
绑定阶段
PreBind
Bind 之前的预处理,例如到 node 上去挂载 volume。
例如,在将 pod 调度到一个 node 之前,先给这个 pod 在那台 node 上挂载一个 network volume。
// PreBindPlugin is an interface that must be implemented by "PreBind" plugins.
// These plugins are called before a pod being scheduled.
type PreBindPlugin interface {
// PreBind is called before binding a pod. All prebind plugins must return
// success or the pod will be rejected and won't be sent for binding.
PreBind(ctx , state *CycleState, p *v1.Pod, nodeName string) *Status
}任何一个 PreBind plugin 失败,都会导致 pod 被 reject,进入到 reserve plugins 的 Unreserve() 方法。
Bind
将 pod 关联到 node,所有 PreBind 完成之后才会进入 Bind。
// https://github.com/kubernetes/kubernetes/blob/v1.28.4/pkg/scheduler/framework/interface.go#L497
// Bind plugins are used to bind a pod to a Node.
type BindPlugin interface {
// Bind plugins will not be called until all pre-bind plugins have completed. Each
// bind plugin is called in the configured order. A bind plugin may choose whether
// or not to handle the given Pod. If a bind plugin chooses to handle a Pod, the
// remaining bind plugins are skipped. When a bind plugin does not handle a pod,
// it must return Skip in its Status code. If a bind plugin returns an Error, the
// pod is rejected and will not be bound.
Bind(ctx , state *CycleState, p *v1.Pod, nodeName string) *Status
}- 所有 plugin 按配置顺序依次执行;
- 每个 plugin 可以选择是否要处理一个给定的 pod;
- 如果选择处理,后面剩下的 plugins 会跳过。也就是最多只有一个 bind plugin 会执行。
PostBind
informational,可选,执行清理操作。
这是一个 informational extension point,也就是无法影响调度决策(没有返回值)。
// https://github.com/kubernetes/kubernetes/blob/v1.28.4/pkg/scheduler/framework/interface.go#L473
// PostBindPlugin is an interface that must be implemented by "PostBind" plugins.
// These plugins are called after a pod is successfully bound to a node.
type PostBindPlugin interface {
// PostBind is called after a pod is successfully bound. These plugins are informational.
// A common application of this extension point is for cleaning
// up. If a plugin needs to clean-up its state after a pod is scheduled and
// bound, PostBind is the extension point that it should register.
PostBind(ctx , state *CycleState, p *v1.Pod, nodeName string)
}插件执行顺序
一般地,自定义插件和默认插件的执行顺序,根据下面规则:
- 如果某个扩展点没有配置对应的扩展,调度框架将使用默认插件中的扩展
- 如果为某个扩展点配置且激活了扩展,则调度框架将先调用默认插件的扩展,再调用配置中的扩展
- 默认插件的扩展始终被最先调用,然后按照 KubeSchedulerConfiguration 中扩展的激活 enabled 顺序逐个调用扩展点的扩展
- 可以先禁用默认插件的扩展,然后在 enabled 列表中的某个位置激活默认插件的扩展,这种做法可以改变默认插件的扩展被调用时的顺序
以上就是 kube-scheduler 的基本原理。
参考文章
kube-scheduler深度剖析与开发(四)
kube-scheduler深度剖析与开发(五)
kube-scheduler深度剖析与开发(六)
K8s 调度框架设计与 scheduler plugins 开发部署示例(2024)



