前言
作为老牌的日志统一收集和查询套件,ELK(又或称ELKB)在实际使用过程中愈发面临着严重的性能问题。其在大数据量写入、同时又混合着查询的情况下性能急剧下降已经是业界公认的事实了。
在此总结一下 ELK 的几大问题:
- 作为 ELKB 链条上的一环,Logstash 是所有组件中最大的短板,它的性能严重不匹配它前面的 Kafka 和后面的 ES。虽然它提供了强大的 grok 解析功能,但这种功能上带来的优势已经被性能太差造成几乎不可用完全抵消了,毕竟能用才是我们的第一目标。
- ES 的429 TOO_MANY_REQUESTS 问题。在我前司的ELK集群使用过程中发现,即便是配置有 256G 内存的物理机作为数据节点(Elasticsearch版本为7.15),在每日几十 TB 的数据量情况下,Logstash 写入 ES 也经常会报 429 TOO_MANY_REQUESTS 拒绝写入错误,无论怎么调 ES 参数、调整 Logstash 批量写入大小都无法解决。
- ES 的数据膨胀问题。一条日志被 Filebeat 收集后会打上很多标签字段,这条日志写入 ES 后会占据额外的存储空间,以及每个字段还会占据索引空间,然而 ES 并不会对数据做压缩。因此一条日志在存入 ES 后大约会放大 1.3~1.5 倍。
Clickhouse 介绍
Clickhouse 是一款高性能列式分布式数据库管理系统,官方对 Clickhouse 进行了测试,发现有下列优势:
- Clickhouse 写入吞吐量大,单服务器日志写入量在 50MB 到 200MB/s,每秒写入超过 60w 记录数,是 ES 的 5 倍以上。在 ES 中比较常见的写 Rejected 导致数据丢失、写入延迟等问题,在 Clickhouse 中不容易发生。
- 查询速度快,官方宣称数据在 pagecache 中,单服务器查询速率大约在 2-30GB/s;没在 pagecache 的情况下,查询速度取决于磁盘的读取速率和数据的压缩率。经测试 Clickhouse 的查询速度比 ES 快 5-30 倍以上。
- Clickhouse比 ES 服务器成本更低。一方面 Clickhouse 的数据压缩比比 ES 高,相同数据占用的磁盘空间只有 ES 的 1/3 到 1/30,节省了磁盘空间的同时,也能有效的减少磁盘IO,这也是 Clickhouse 查询效率更高的原因之一;另一方面 Clickhouse 比 ES 占用更少的内存,消耗更少的 CPU 资源。我们预估用 Clickhouse 处理日志可以将服务器成本降低一半。
下面是一组Clickhouse和Elasticsearch的对比
| 支持功能 | Elasticsearch | Clickhouse |
|---|---|---|
| 开发语言 | java | c++ |
| 存储类型 | 文档存储 | 列式数据库 |
| 分布式支持 | 分片和副本 | 分片和副本 |
| 扩展性 | 高 | 高 |
| 写入速度 | 慢 | 快 |
| CPU/内存占用 | 高 | 低 |
| 存储占用(54G日志导入) | 高 94G(174%) | 低 23G(42.6%) |
| 精确匹配查询速度 | 一般 | 快 |
| 模糊匹配查询速度 | 快 | 慢 |
| 权限管理 | 支持 | 支持 |
| 查询难度 | 低 | 高 |
| 可视化支持 | 高(Kibana) | 低(客户端工具) |
| 维护难度 | 低 | 高 |
部署 CKB
CKB是 Clickhouse + Kafka + Filebeats的缩写。在这一套工具里,减少了最大的短板 Logstash,部分牺牲了 grok 的便利性,但 Logstash 里有些简单的功能 Filebeat 已经可以支持了(比如添加/删除/转换字段)。
部署 Kafka
本文选择的版本是 kafka_2.13-3.7.0。在这个版本里 Kafka 还需要 Zookeeper 的支持,在 4.0 版本之后就不需要 Zookeeper 了(https://kafka.apache.org/documentation/#zk)。
部署的时候可以使用 Kafka 自带的 Zookeeper,也可以使用外部单独部署的 Zookeeper。本文使用三节点虚拟机部署 Kafka,同时使用 Kafka 自带的 Zookeeper,节点角色规划如下:
部署 Kafka 图形化界面 KOWL
KOWL 是一个开源的Kafka图形化界面,本文使用podman部署:
podman run -d -p 8080:8080 -e KAFKA_BROKERS=192.168.126.47:9092 quay.io/cloudhut/kowl:master浏览器打开界面:http://192.168.126.47:8080
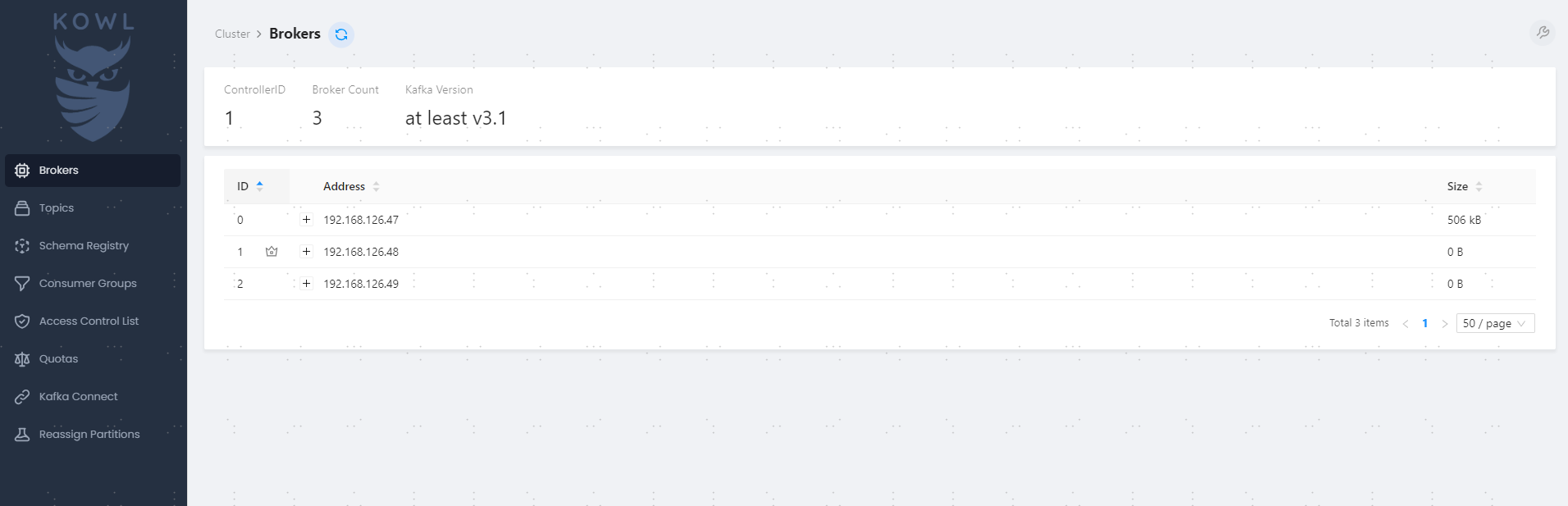
能看到集群的节点列表、Topics、Consumer Groups等,该有的功能基本都有。
部署 filebeat 收集日志
安装filebeat略。添加一个采集器配置:
filebeat.inputs:
- type: filestream
id: my-filestream-id
enabled: true
paths:
- /var/log/*.log
- /var/log/syslog
filebeat.config.modules:
path: ${path.config}/modules.d/*.yml
reload.enabled: false
setup.template.settings:
index.number_of_shards: 1
output.kafka:
enabled: true
hosts: ["192.168.126.47:9092","192.168.126.48:9092","192.168.126.49:9092"]
#username: ""
#password: ""
partition.round_robin:
reachable_only: true
#sasl.mechanism: "SCRAM-SHA-256"
topic: "FIOPS_LOGS"
processors:
- add_host_metadata:
when.not.contains.tags: forwarded
path.logs: /var/log/output.kafka 配置了 filebeat 的输出目标是上一步部署的 kafka,为简便起见,kafka 未做用户权限设置。topic 自己随便起个名字。filebeat 支持自动在 kafka 创建不存在的 topic,并使用默认值设置 topic 的分区数等配置。
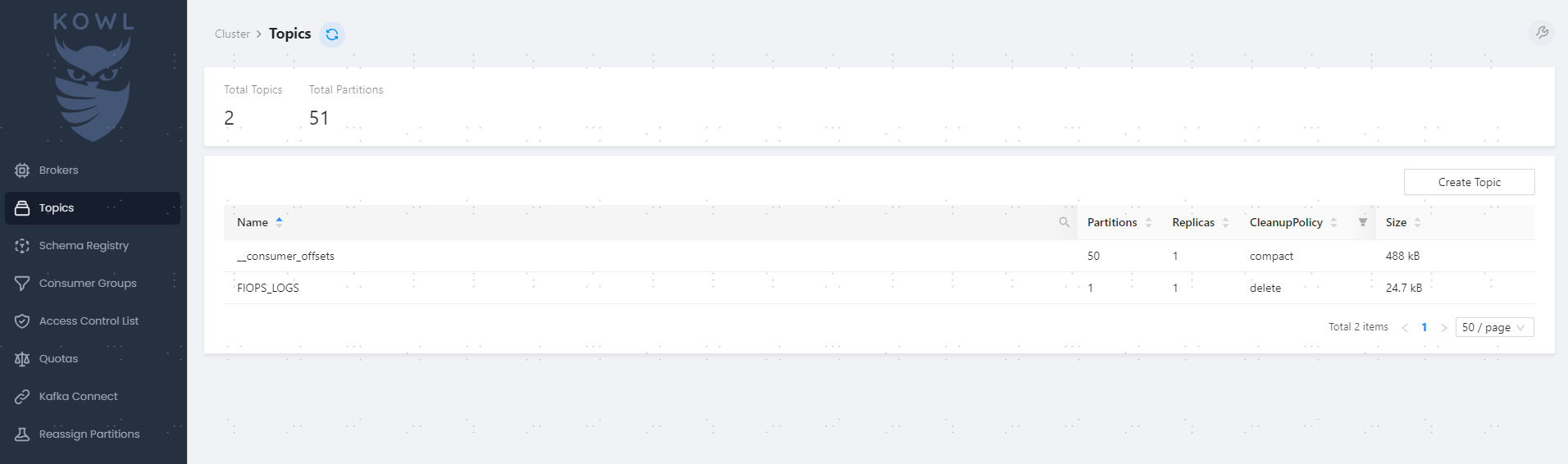
启动 filebeat 后,在 KOWL 界面查看 topic 已经自动创建好了:
进入topic,查看消息详情:
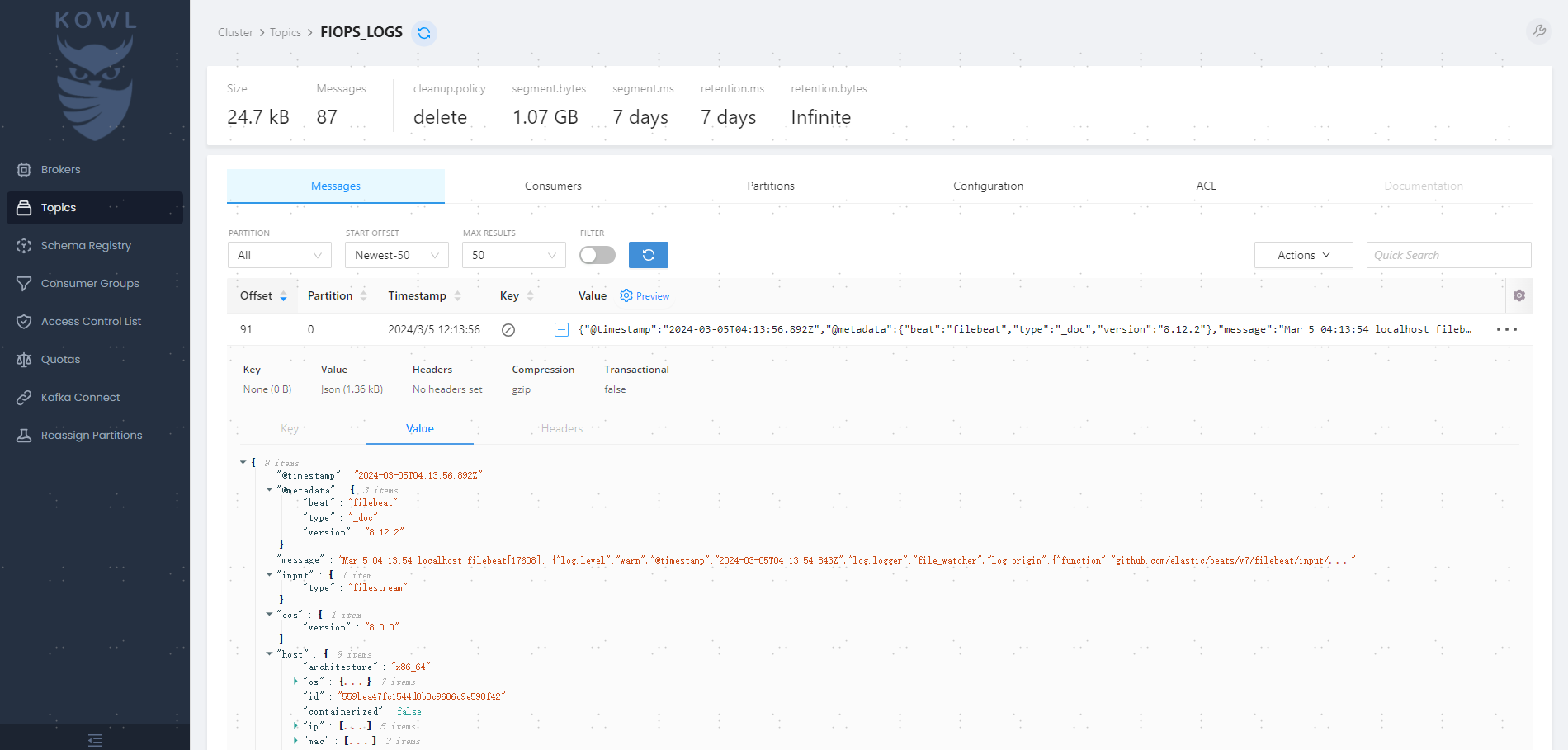
可以看到filebeat采上来的日志长这样:
{
"@timestamp": "2024-03-05T09:21:28.147Z",
"@metadata": {
"beat": "filebeat",
"type": "_doc",
"version": "8.12.2"
},
"agent": {
"ephemeral_id": "ec85a63d-6560-4cf1-802c-c188a9a214b9",
"id": "3c4ba1f6-6e54-4d7b-b6cf-0433fb86c6af",
"name": "kafka-1",
"type": "filebeat",
"version": "8.12.2"
},
"ecs": {
"version": "8.0.0"
},
"host": {
"ip": [
"192.168.126.47",
"fe80::20c:29ff:fed6:7f4b",
"10.88.0.1",
"fe80::8fd:b4ff:fe26:d26d",
"fe80::74a6:dbff:fe73:4e14"
],
"mac": [
"00-0C-29-D6-7F-4B",
"0A-FD-B4-26-D2-6D",
"76-A6-DB-73-4E-14"
],
"hostname": "kafka-1",
"architecture": "x86_64",
"name": "kafka-1",
"os": {
"version": "22.04.3 LTS (Jammy Jellyfish)",
"family": "debian",
"name": "Ubuntu",
"kernel": "5.15.0-91-generic",
"codename": "jammy",
"type": "linux",
"platform": "ubuntu"
},
"id": "559bea47fc1544d0b0c9606c9e590f42",
"containerized": false
},
"log": {
"offset": 6846610,
"file": {
"inode": "4194448",
"path": "/var/log/syslog",
"device_id": "64769"
}
},
"message": "Mar 5 09:21:24 localhost filebeat[17608]: {\"log.level\":\"info\",\"@timestamp\":\"2024-03-05T09:21:24.822Z\",\"log.logger\":\"monitoring\",\"log.origin\":{\"function\":\"github.com/elastic/beats/v7/libbeat/monitoring/report/log.(*reporter).logSnapshot\",\"file.name\":\"log/log.go\",\"file.line\":187},\"message\":\"Non-zero metrics in the last 30s\",\"service.name\":\"filebeat\",\"monitoring\":{\"metrics\":{\"beat\":{\"cgroup\":{\"memory\":{\"mem\":{\"usage\":{\"bytes\":51556352}}}},\"cpu\":{\"system\":{\"ticks\":6970,\"time\":{\"ms\":10}},\"total\":{\"ticks\":12090,\"time\":{\"ms\":10},\"value\":12090},\"user\":{\"ticks\":5120}},\"handles\":{\"limit\":{\"hard\":524288,\"soft\":524288},\"open\":14},\"info\":{\"ephemeral_id\":\"ec85a63d-6560-4cf1-802c-c188a9a214b9\",\"uptime\":{\"ms\":18600109},\"version\":\"8.12.2\"},\"memstats\":{\"gc_next\":40875136,\"memory_alloc\":20938616,\"memory_total\":483685464,\"rss\":47435776},\"runtime\":{\"goroutines\":44}},\"filebeat\":{\"events\":{\"active\":0,\"added\":1,\"done\":1},\"harvester\":{\"open_files\":2,\"running\":2}},\"libbeat\":{\"config\":{\"module\":{\"running\":0}},\"output\":{\"events\":{\"acked\":1,\"active\":0,\"batches\":1,\"total\":1}},\"outputs\":{\"kafka\":{\"bytes_read\":54,\"bytes_write\":1402}},\"pipeline\":{\"clients\":2,\"events\":{\"active\":0,\"published\":1,\"total\":1},\"queue\":{\"acked\":1}}},\"registrar\":{\"states\":{\"current\":0}},\"system\":{\"load\":{\"1\":0.16,\"15\":0.25,\"5\":0.22,\"norm\":{\"1\":0.08,\"15\":0.125,\"5\":0.11}}}},\"ecs.version\":\"1.6.0\"}}",
"input": {
"type": "filestream"
}
}部署 Clickhouse
本文选择的版本是23.8.2。Clickhouse 也需要一个 Zookeeper,默认也可使用 Clickhouse 内置的 ZK。
Clickhouse 集群支持分片+副本,本文不对 Clickhouse 架构做过多介绍。本文使用 2 节点虚机部署 Clickhouse,只设置1分片、2副本。同时使用Clickhouse自带的Zookeeper,节点角色规划如下:
| IP | 安装软件 | 角色 |
|---|---|---|
| 192.168.126.41 | Clickhouse-23.8.2, zookeeper | shard0-replica0, zk_id=0 |
| 192.168.126.42 | Clickhouse-23.8.2, zookeeper | shard0-replica1, zk_id=1 |
本文使用ansible-playbook自动化部署Clickhouse,具体playbook可联系作者获取。
使用Clickhouse自带的clickhouse-client连接集群:
clickhouse-client -h localhost输入密码后即可进入控制台。
配置 Clickhouse 连接 Kafka 总共需要三步:
- 创建一个 Kafka 引擎表用于连接 Kafka
- 创建一个 MergeTree 或 MergeTree 系列类型的本地表作为数据表,实际存储从 kafka 消费过来的数据
- 创建一个物化视图关联 Kafka 引擎表和数据表,这样才能把 Kafka 消费的实际数据存入
以上三个步骤缺一不可
创建一个Kafka引擎表
Kafka 引擎表的字段必须和 Kafka 采上来的日志格式相匹配,日志格式是 json 格式的,kafka_format 可设置成 JSONEachRow。注意上一节里采上来的 message 是一个多层的复杂 json 格式,我们可以只选择第一层 key(即 @timestamp、message、host、log……)作为 Kafka 引擎表的字段,这样第一层的 value(可以还是一个复杂json)会作为字符串整体存入。message 里不在表字段出现的 key,或者解析失败的字段会直接被丢弃。Kafka 引擎表一般以 _queue 结尾。
create table kafka_fiops_logs_queue (
`@timestamp` String,
`message` String,
`host` String,
`log` String
) ENGINE = Kafka()
SETTINGS
kafka_broker_list = '192.168.126.47:9092',
kafka_topic_list = 'FIOPS_LOGS',
kafka_group_name = 'fiopsgroup',
kafka_format = 'JSONEachRow'注意这里 @timestamp 没有设置成 Datetime 类型,是因为 Clickhouse 的 Datetime 类型不能解析 message 的 @timestamp 格式 2024-03-05T09:21:28.147Z,所以退而求其次使用了 String 类型。
创建一个MergeTree引擎的数据表
可以使用 MergeTree、ReplicatedMergeTree 等类型作为实际的数据表,其字段必须和 Kafka 引擎表保持一致。
create table kafka_fiops_logs_table on cluster default(
`@timestamp` String,
`message` String,
`host` String,
`log` String
) ENGINE = ReplicatedMergeTree('/clickhouse/tables/{shard}/kafka_fiops_logs_table', 'kafka_fiops_logs_table-{replica}')
order by `@timestamp`创建一个物化视图
create materialized view fiops_logs_consumer to kafka_fiops_logs_table as select * from kafka_fiops_logs_queue以上三个步骤均完成以后,打开 KOWL 的 topic,切换到 Consumers 页面可以看到多出了一个 consumer group fiopsgroup,正是我们 Kafka 引擎表里设置的kafka_group_name。

查询数据表,看是否已经写入
select * from kafka_fiops_logs_table limit 1;
SELECT *
FROM kafka_fiops_logs_table
LIMIT 1
Query id: b9424a2d-fb20-43a9-b584-72351b2e1017
┌─@timestamp───────────────┬─message──────────────────────────────────────────────────────────────────────────────────────────────────────────────┬─host───────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┬─log────────────────────────────────────────────────────────────────────────────────────────┐
│ 2024-03-05T04:11:24.841Z │ Mar 5 04:11:06 localhost systemd[1]: Stopping Filebeat sends log files to Logstash or directly to Elasticsearch.... │ {"name":"kafka-1","containerized":false,"ip":["192.168.126.47","fe80::20c:29ff:fed6:7f4b","10.88.0.1","fe80::8fd:b4ff:fe26:d26d","fe80::74a6:dbff:fe73:4e14"],"mac":["00-0C-29-D6-7F-4B","0A-FD-B4-26-D2-6D","76-A6-DB-73-4E-14"],"hostname":"kafka-1","architecture":"x86_64","os":{"kernel":"5.15.0-91-generic","codename":"jammy","type":"linux","platform":"ubuntu","version":"22.04.3 LTS (Jammy Jellyfish)","family":"debian","name":"Ubuntu"},"id":"559bea47fc1544d0b0c9606c9e590f42"} │ {"offset":5176394,"file":{"path":"/var/log/syslog","device_id":"64769","inode":"4194448"}} │
└──────────────────────────┴──────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┴────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┴────────────────────────────────────────────────────────────────────────────────────────────┘
1 row in set. Elapsed: 0.012 sec. Processed 3.09 thousand rows, 3.68 MB (263.09 thousand rows/s., 313.10 MB/s.)
Peak memory usage: 4.42 MiB.优化日志采集字段
filebeat 采上来的日志添加了很多我们不需要的字段,会占据很多额外空间。丢弃一些字段的功能原来是由 Logstash 的filter 来完成的,不过 filebeat 现在也支持。修改filebeat 配置文件:
filebeat.inputs:
- type: filestream
id: my-filestream-id
enabled: true
paths:
- /var/log/*.log
- /var/log/syslog
filebeat.config.modules:
path: ${path.config}/modules.d/*.yml
reload.enabled: false
setup.template.settings:
index.number_of_shards: 1
output.kafka:
enabled: true
hosts: ["192.168.126.47:9092","192.168.126.48:9092","192.168.126.49:9092"]
#username: ""
#password: ""
partition.round_robin:
reachable_only: true
#sasl.mechanism: "SCRAM-SHA-256"
topic: "FIOPS_LOGS"
processors:
- add_host_metadata:
when.not.contains.tags: forwarded
- move_fields:
from: "host"
fields: ["hostname", "ip"]
to: ""
- move_fields:
from: "log"
fields: ["file"]
to: ""
- move_fields:
from: "file"
fields: ["path"]
to: ""
- extract_array:
field: "ip"
mappings:
hostip: 0
- drop_fields:
fields: ["metadata", "agent", "ecs", "input", "log", "host", "file", "ip"]重启filebeat,打开KOWL查看新的message现在长这样:
{
"@timestamp": "2024-03-05T09:42:39.176Z",
"@metadata": {
"beat": "filebeat",
"type": "_doc",
"version": "8.12.2"
},
"message": "Mar 5 09:42:37 localhost conmon[12590]: {\"level\":\"info\",\"ts\":\"2024-03-05T09:42:37.357Z\",\"msg\":\"assigning partitions\",\"source\":\"kafka_client\",\"why\":\"new assignments from direct consumer\",\"how\":\"assigning everything new, keeping current assignment\",\"input\":\"FIOPS_LOGS[0{0 e-1 ce0}]\"}",
"path": "/var/log/syslog",
"hostip": "192.168.126.47",
"hostname": "kafka-1"
}已经去掉了没用的字段。现在修改 Clickhouse 里的表结构,使其重新适配 message。
alter table kafka_fiops_logs_table add column hostname String;
alter table kafka_fiops_logs_table add column hostip String;
alter table kafka_fiops_logs_table add column path String;
alter table kafka_fiops_logs_table drop column host;
alter table kafka_fiops_logs_table drop column log;Kafka 引擎表不支持 add column,只能删表重建
drop table kafka_fiops_logs_queue
create table kafka_fiops_logs_queue(
`@timestamp` String,
`message` String,
`hostname` String,
`hostip` String,
`path` String
) ENGINE = Kafka()
SETTINGS
kafka_broker_list = '192.168.126.47:9092',
kafka_topic_list = 'FIOPS_LOGS',
kafka_group_name = 'fiopsgroup',
kafka_format = 'JSONEachRow'重新查询:
select * from kafka_fiops_logs_table order by `@timestamp` desc limit 1;
SELECT *
FROM kafka_fiops_logs_table
ORDER BY `@timestamp` DESC
LIMIT 1
Query id: 22b83419-1949-461a-a688-67bbc8eef9f2
┌─@timestamp───────────────┬─message────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┬─hostname─┬─hostip─────────┬─path────────────┐
│ 2024-03-05T09:49:13.266Z │ Mar 5 09:49:12 localhost conmon[12590]: {"level":"info","ts":"2024-03-05T09:49:12.097Z","msg":"assigning partitions","source":"kafka_client","why":"new assignments from direct consumer","how":"assigning everything new, keeping current assignment","input":"FIOPS_LOGS[0{0 e-1 ce0}]"} │ kafka-1 │ 192.168.126.47 │ /var/log/syslog │
└──────────────────────────┴────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┴──────────┴────────────────┴─────────────────┘
1 row in set. Elapsed: 0.008 sec. Processed 3.21 thousand rows, 2.04 MB (401.69 thousand rows/s., 255.17 MB/s.)
Peak memory usage: 5.79 MiB.增加数据分区
类似 MySQL、TiDB 这些关系型数据库,Clickhouse 也支持数据分区(Partition),可以将上面创建的数据表按照日期进行每月分区,这里用到了函数 toYYYYMM,可将 Date 或者 Datetime 类型的字段转换成 年月,但 kafka_fiops_logs_table 表里的 @timestamp 字段由于解析的原因已经被我们设置成了 String 类型,没法直接用 toYYYYMM 函数,需要先把 String 转成 Datetime,用到了函数 parseDateTimeBestEffort。写法如下:
create table kafka_fiops_logs_table on cluster default(
`@timestamp` String,
`message` String,
`hostname` String,
`hostip` String,
`path` String
) ENGINE = ReplicatedMergeTree('/clickhouse/tables/{shard}/kafka_fiops_logs_table', 'kafka_fiops_logs_table-{replica}')
PARTITION BY toYYYYMM(parseDateTimeBestEffort(`@timestamp`))
order by `@timestamp`


